ai-ml
YOLOv9 Cow Detection: From Docker to Edge Deployment on Raspberry Pi
How we optimized a cattle detection system for resource-constrained Raspberry Pi 3B+ devices, achieving 91.7% mAP while reducing storage requirements by 63%.
January 20, 2025 · 6 min read · Carlos Salguero

Deploying computer vision models on edge devices is a balancing act between accuracy, speed, and resource constraints. In this post, I'll share our journey optimizing a cattle detection system for Raspberry Pi 3B+ devices at CAETEC's dairy facility—going from a Docker-containerized YOLOv8x deployment to a lean YOLOv9c implementation that runs on just 512MB of RAM.
The Challenge: Edge AI in Agriculture
The CowVision project started with a clear goal: automate cow detection in the milking process at CAETEC's dairy facility, a laboratory dedicated to agricultural learning. Our initial implementation used a Raspberry Pi 4 (4GB RAM) running YOLOv8x in a Docker container, producing annotated images uploaded to AWS S3.
It worked—but when we needed to deploy to client facilities with Raspberry Pi 3B+ devices (512MB RAM, 1.4GHz CPU, 16GB storage), we hit serious constraints:
- Docker overhead: The container alone consumed 1.2GB of storage
- Memory pressure: YOLOv8x demanded 250MB just for the model
- Slow inference: 420ms per frame on the Pi 3B+
We needed a complete rethink of our deployment strategy.
Why YOLOv9c Over YOLOv8x?
After extensive benchmarking, we chose YOLOv9c for three empirically validated reasons:
| Metric | YOLOv8x | YOLOv9c | Improvement |
|---|---|---|---|
| Inference Time | 420ms | 360ms | 15% faster |
| RAM Usage | 250MB | 200MB | 20% smaller |
| Model Size | 260.16MB | 96.82MB | 63% smaller |
| mAP@0.5 | 90.2% | 91.7% | +1.5% |
The key innovation in YOLOv9 is Programmable Gradient Information (PGI), which solves information bottleneck problems present in YOLOv8. This architectural improvement enables better feature extraction even on low-power devices.
Deployment Strategy: Docker to Virtual Environments
The biggest win wasn't the model change—it was rethinking our deployment approach entirely.
Before: Docker Containerization
Total Storage: 1.2GB+
├── Docker runtime overhead
├── Base image (Ubuntu/Python)
├── Dependencies
└── YOLOv8x model (260MB)
After: Python Virtual Environment
Total Storage: ~150MB
├── Python venv (minimal)
├── Ultralytics + dependencies
└── YOLOv9c model (97MB)
This shift eliminated 200MB+ of container overhead while dramatically simplifying maintenance for non-technical users at the dairy facilities.
Output Optimization
We also optimized what the system outputs:
- Before: 500KB annotated JPEG images per detection
- After: 1KB text-only logs (with optional visual output via runtime flags)
This 500x reduction in output size makes a real difference when running 24/7 on limited storage.
Performance Deep Dive
We ran comprehensive benchmarks comparing four configurations: YOLOv8x base, YOLOv9c base, and both architectures with custom-trained weights (best.pt).
Base Model Comparison
| Metric | YOLOv8x Base | YOLOv9c Base |
|---|---|---|
| Inference Time | 35.00ms | 26.20ms |
| CPU Usage | 1.50% | 7.11% |
| Model Size | 260.16MB | 96.82MB |
YOLOv9c is significantly faster and smaller, though it uses more CPU. For our use case, the storage savings far outweigh the CPU difference.
Custom-Trained Models
| Metric | YOLOv8x Best | YOLOv9c Best |
|---|---|---|
| Inference Time | 24.87ms | 25.42ms |
| CPU Usage | 6.46% | 6.98% |
| Model Size | 96.59MB | 96.59MB |
Detection Quality Comparison
The real difference shows in actual detection outputs. Here's a side-by-side comparison:

Key observations from our testing:
- Base models: YOLOv9c detected more cows with higher confidence (0.86 vs 0.76)
- Custom-trained models: Both achieve similar confidence scores, but YOLOv9c shows more precise bounding box placement
- Low-light performance: YOLOv9c handles the challenging lighting conditions in dairy facilities significantly better
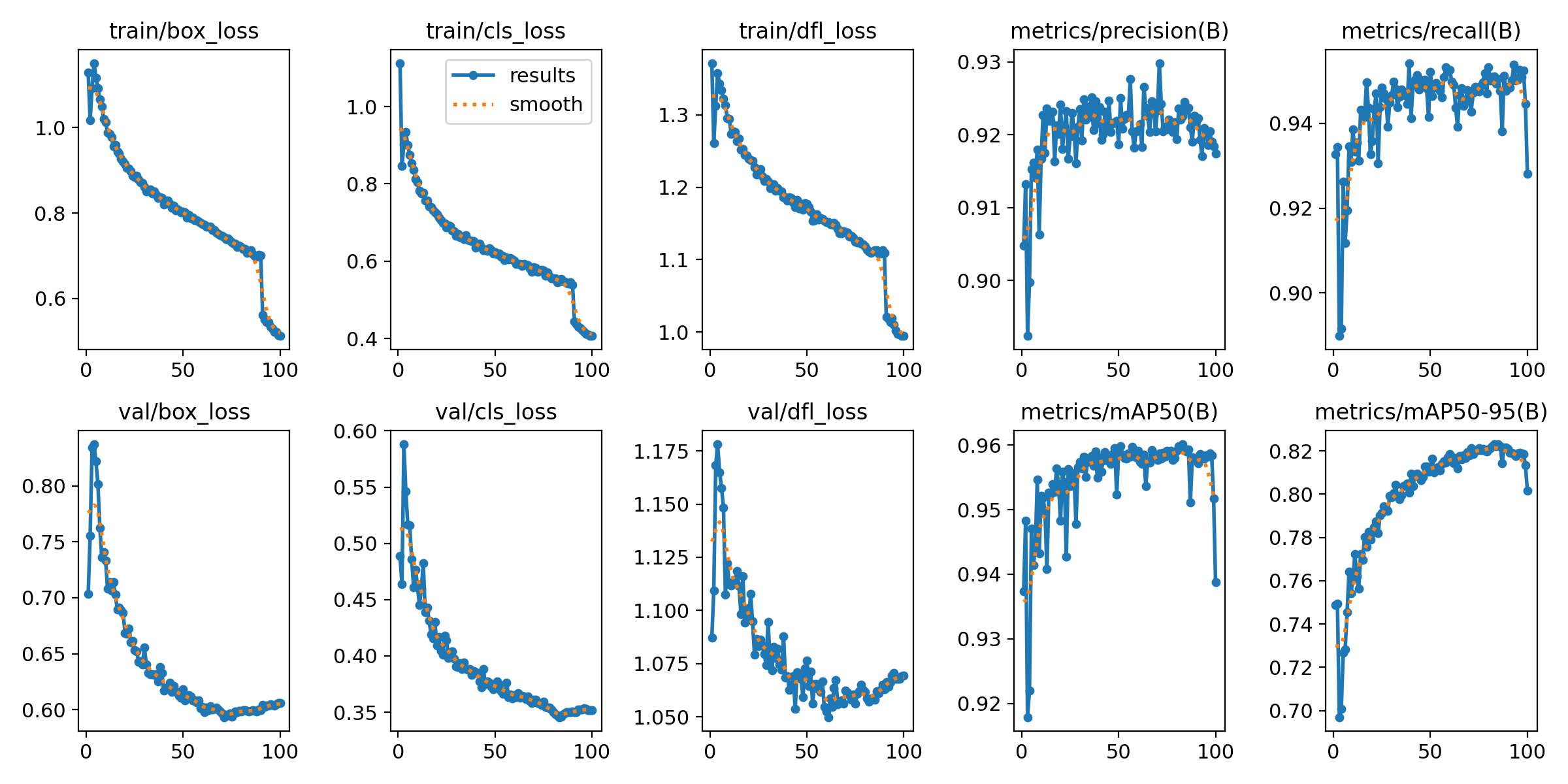
Training Results
We trained the YOLOv9c model on CAETEC's dataset of 1,200 annotated images over 100 epochs. The training progression shows stable convergence:
The confusion matrix confirms robust detection capabilities:
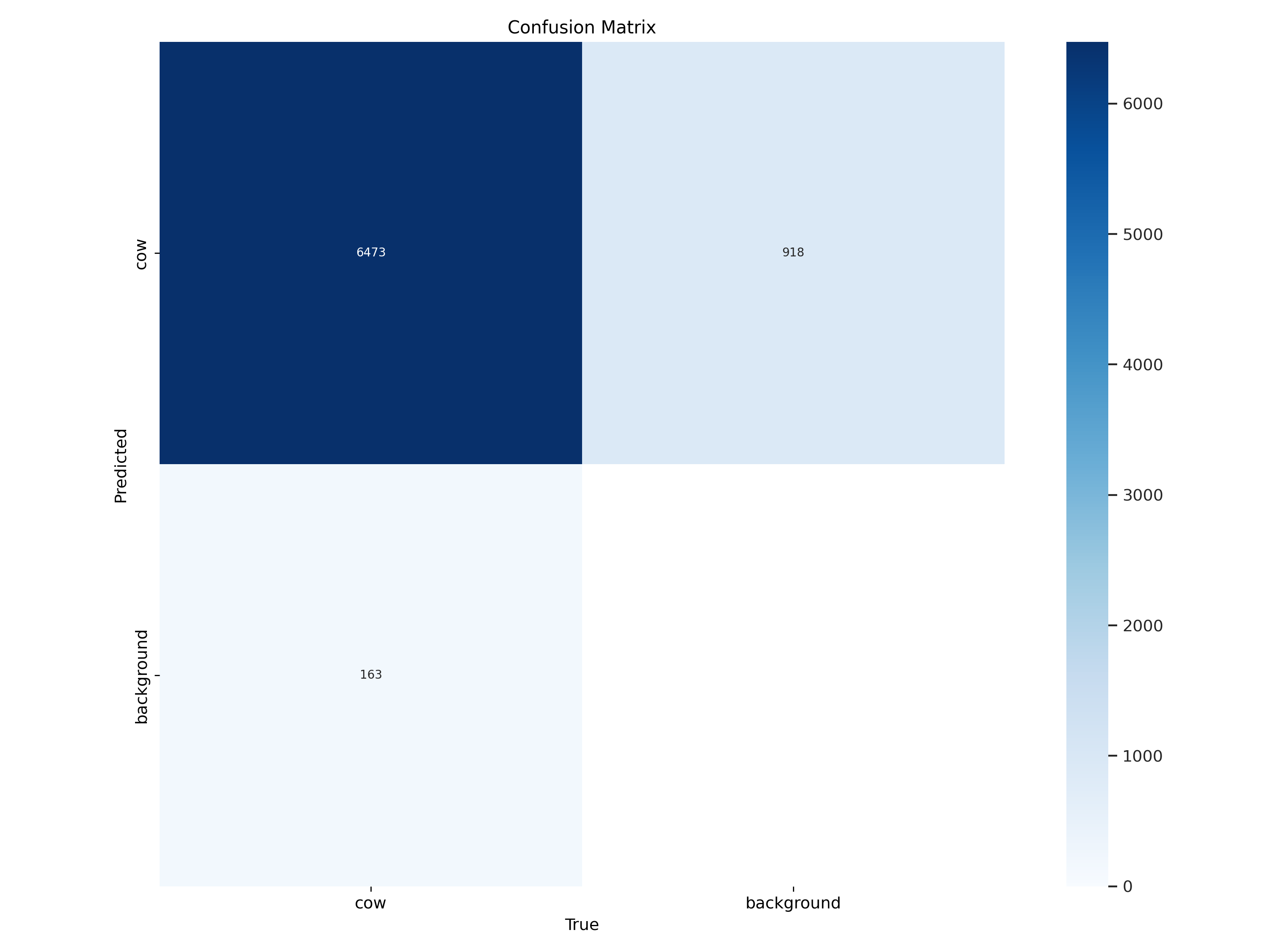
The high true positive rate with minimal false negatives indicates the model handles the variable lighting conditions typical of dairy facilities.
Performance Visualization
Here's a visual summary of the performance trade-offs:
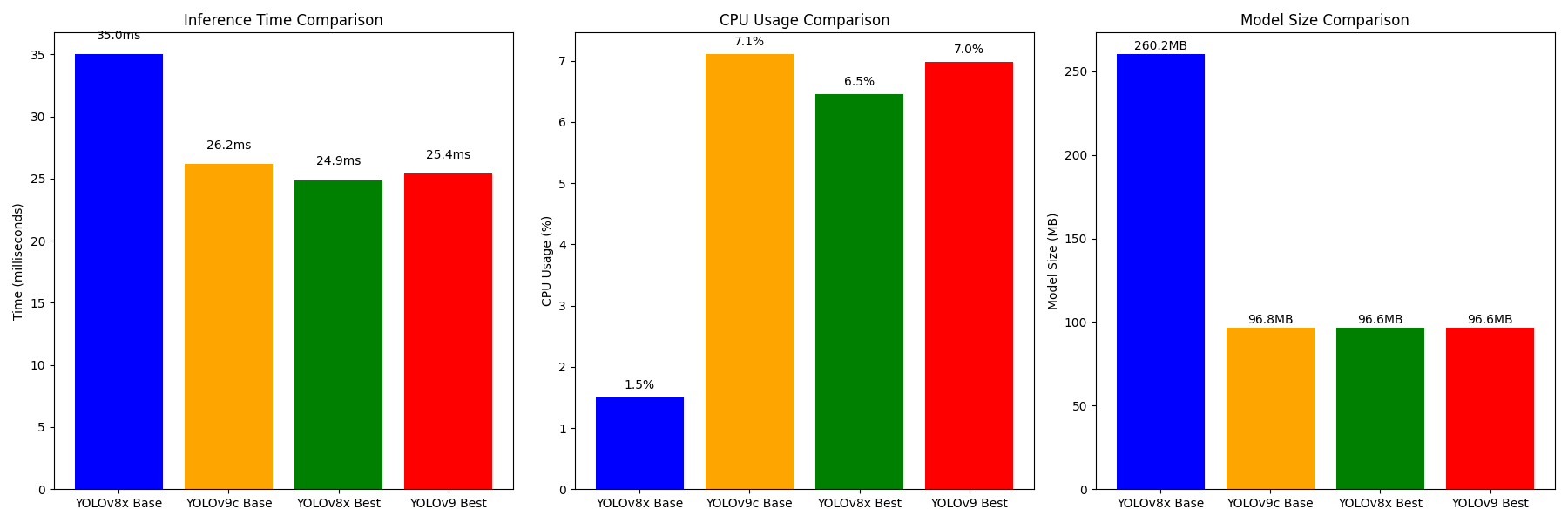
The charts reveal the key trade-offs:
- Inference speed: YOLOv9c base is fastest; custom training equalizes both architectures
- CPU utilization: YOLOv8x is more CPU-efficient, but the difference is marginal with custom weights
- Model size: YOLOv9c base is dramatically smaller; custom training equalizes both
Key Takeaways
-
Architecture matters for edge deployment: YOLOv9's PGI architecture provides tangible benefits on resource-constrained hardware—15% faster inference and 63% smaller model size.
-
Custom training levels the playing field: With domain-specific training, both architectures achieve similar speeds, but YOLOv9c maintains superior detection quality.
-
Deployment strategy is as important as model choice: Switching from Docker to virtual environments saved more storage than the model optimization itself.
-
Low-light performance is critical for 24/7 monitoring: YOLOv9c's architectural improvements translate to better detection in challenging lighting conditions.
-
Simple beats complex for agricultural deployments: Non-technical users need straightforward maintenance procedures. Virtual environments are easier to understand and troubleshoot than containers.
Future Work
Several opportunities for further optimization:
| Enhancement | Expected Benefit |
|---|---|
| INT8 Quantization | Further memory reduction, faster inference |
| Multi-Model Pipeline | YOLOv8x for detection + YOLOv9c for classification |
| Edge-Cloud Hybrid | Selective cloud offloading for advanced analytics |
| Extended Dataset | More lighting conditions, weather, camera angles |
Conclusion
This project demonstrates that edge AI for precision livestock farming is not just feasible—it's practical. By carefully selecting the right model architecture (YOLOv9c) and deployment strategy (virtual environments over containers), we achieved:
- 91.7% mAP detection accuracy
- 360ms inference time on Raspberry Pi 3B+
- ~150MB total deployment size (down from 1.2GB)
- 24/7 reliable operation in a production dairy environment
The CowVision system is now running at CAETEC's facility, providing real-time cow counting data that drives operational improvements in the milking process.
Interested in edge AI deployments for agricultural applications? Feel free to reach out—I'd love to discuss computer vision in precision farming!
Enjoyed this article?
Explore more posts or get in touch to discuss ideas.